Strange Loop 2014:Turning the Database Inside Out with Apache Samza
September 18, 2014: 2:00 PM – 2:40 PM

From the promotional materials:
Turning the Database Inside Out with Apache Samza
Databases are global, shared, mutable state. That’s the way it has been since the 1960s, and no amount of NoSQL has changed that. However, most self-respecting developers have got rid of mutable global variables in their code long ago. So why do we tolerate databases as they are?
A more promising model, used in some systems, is to think of a database as an always-growing collection of immutable facts. You can query it at some point in time — but that’s still old, imperative style thinking. A more fruitful approach is to take the streams of facts as they come in, and functionally process them in real-time.
This talk introduces Apache Samza, a distributed stream processing framework developed at LinkedIn. At first it looks like yet another tool for computing real-time analytics, but it’s more than that. Really it’s a surreptitious attempt to take the database architecture we know, and turn it inside out.
At its core is a distributed, durable commit log, implemented by Apache Kafka. Layered on top are simple but powerful tools for joining streams and managing large amounts of data reliably.
What we have to gain from turning the database inside out? Simpler code, better scalability, better robustness, lower latency, and more flexibility for doing interesting things with data. After this talk, you’ll see the architecture of your own applications in a completely new light.
Martin Kleppmann is a committer on Apache Samza (a distributed stream processing framework), software engineer at LinkedIn, and author at O’Reilly (currently writing a book on designing data-intensive applications). He invented the infamous “LinkedIn Intro” email proxy. Previously he co-founded and sold two startups, Rapportive and Go Test It. He is based in Cambridge, UK.
My personal notes:
If you take a look at my original Strange Loop 2014 post on session planning for the event, the timeslot of this event had no competitors. In retrospect, while this session focused on the database and interfacing with databases, discussion topics involved both database architecture and application architecture, which touch upon much of what I do as a consultant on client projects.
As I attended and recently revisited the session, I thought a lot about how application development has both changed and stayed the same over the years of my professional career. One area of project work has been especially on my mind, since it includes work on database replication, although I have also thought a bit about my use of JPA/Hibernate first and second level caches over the years.
In addition to Apache Samza, this talk also mentioned a number of other technologies, the most of which centered on Apache Kafka, since the two products work together. Other specific technologies mentioned include Memcached, Redis, Meteor, Firebase, Datomic, LevelDB, RocksDB, Tango, and Apache Storm. The talk also touched upon Kappa and Lambda architectures.
- a talk about database architecture and application architecture
- related to an open source project called Apache Samza that Kleppmann has been working on
- Kleppmann was with LinkedIn working on Apache Samza until just recently
- currently on sabbatical and writing an O'Reilly book called "Designing Data-Intensive Applications"
- the idea of this book is to provide a conceptual, broad overview of how data systems actually work – looking at databases, caches, indexes, batch processing, stream processing – and how these fit together
- Kleppmann pointed out that this presentation is intended to be database agnostic, and does not draw a distinction between "relational" and "NoSQL"
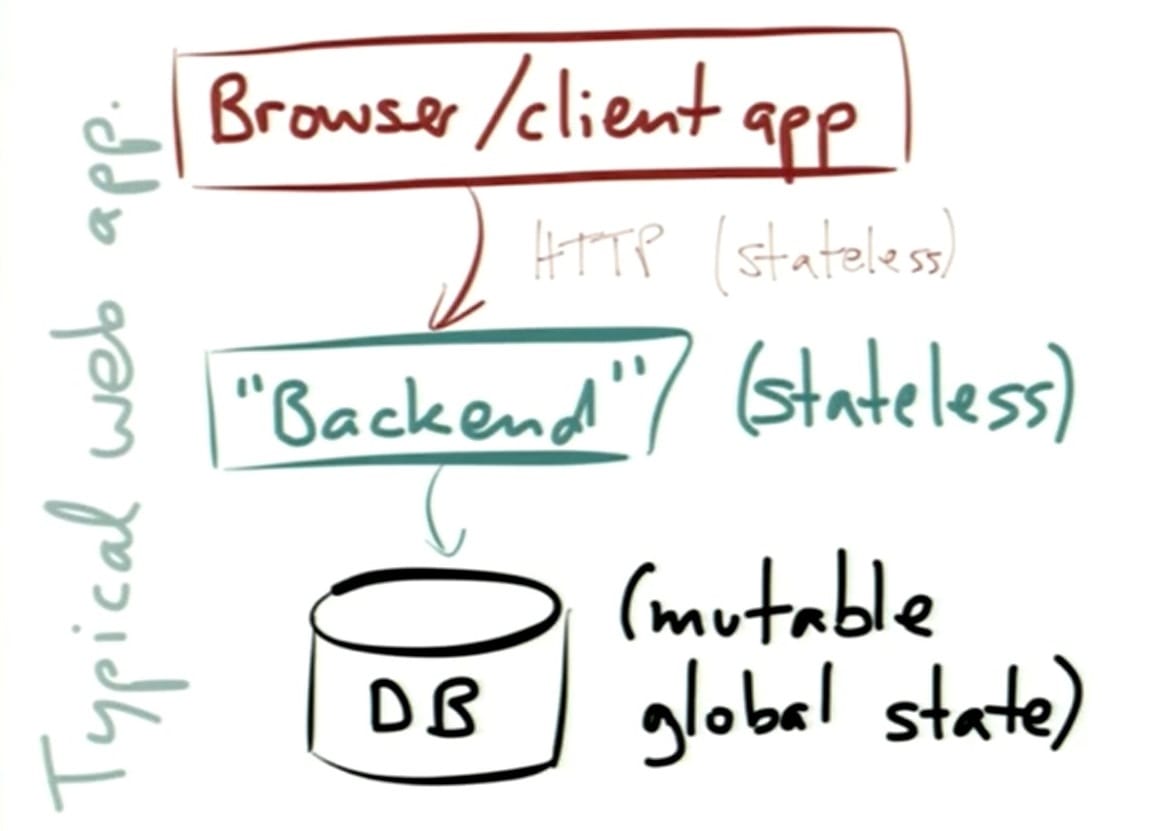
- the stereotypical web application has clients – web browsers or mobile apps – that are talking to some type of server side system which might call a "back-end" that includes business logic which interfaces with a database
- this type of application is typically constructed with an application layer – a stateless backend – which provides a lot of advantages
- you can run more and more processes in parallel with your backend logic, and if you need to handle more requests, you can just spin up more instances, each of which is qualified to handle a particular incoming request, because state will be looked up per request in the database
- this works well with HTTP as well, because HTTP is a stateless protocol
- the problem with this approach is that the state needs to go somewhere, so the state goes in the database
- the database is typically used as a giant, global, shared, mutable state – the kind of horrendous thing that we've been trying to get rid of for ages in shared memory concurrency
- a lot of work has been put into all of the models that have been built to create concurrent systems that try to get away from shared memory concurrency where you have to worry about locking, race conditions, concurrent modification deadlocks etc
- with databases, however, we are still stuck with this giant, global, shared, mutable state
- the momentum behind building systems this way is essentially because it's always been that way, and we don't have the tools to do differently
- what are the other possibilities?
- Kleppmann proposes taking a look at 4 different examples concerning what databases currently do, and things that we do with databases, to give us hints as to the direction we can go
- example #1 – replication – where you have copies of your data on multiple machines, multiple nodes, and it's the job of the database to keep these in sync – the common architecture involves writing to a designated node you call master or leader, and that one is in charge of copying to followers or slaves
- a lot of systems are built this way, but let's take a look at what actually happens
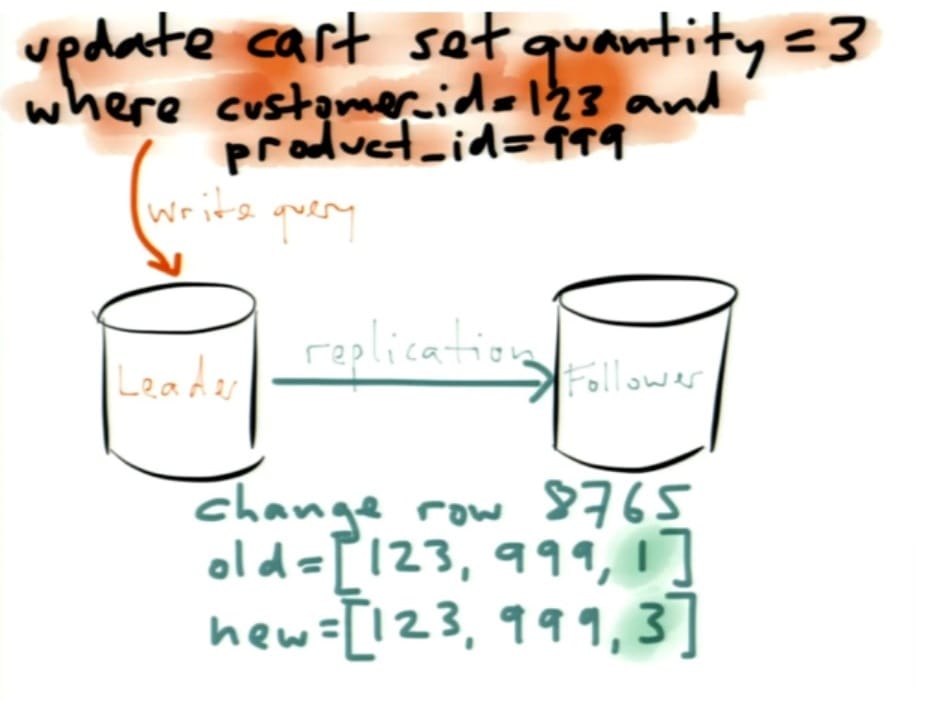
- Kleppmann goes over a shopping cart example that makes use of a table with 3 columns – customer_id, product_id, and quantity
- an update is made to quantity from 1 to 3
- there are different ways that this update can be replicated – different databases implement this in various ways – but the leader database creates an event which indicates that for some row identifier, this is the old state and this is the new state
- what is actually happening here is at a point in time and is an immutable event or fact
- internally, the database is already using the idea of immutability

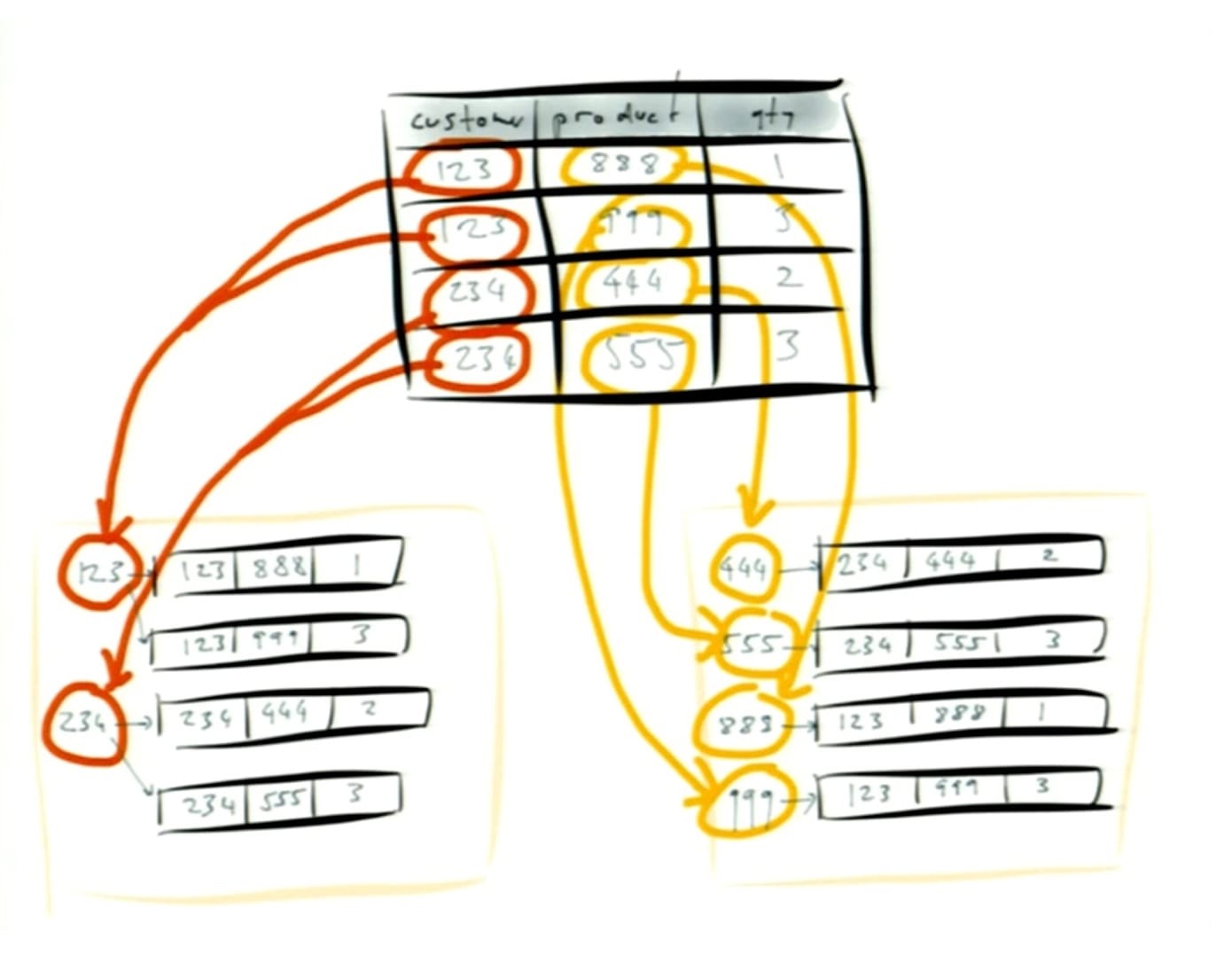
- example #2 – secondary indexes – considering the table from the first example, if you want to query by different fields you will want to create additional indexes to find matching rows efficiently
- so what you would do here is create indexes for example on customer_id and product_Id
- the database will create an auxillary data structure for each index created, usually a key-value type structure
- the database simply knows what to do when data changes and the indexes need to be updated – and this is done in a transactional way
- what's cool is that some databases permit that this be done concurrently with issuing write queries – for example PostgreSQL has a "CREATE INDEX CONCURRENTLY" command
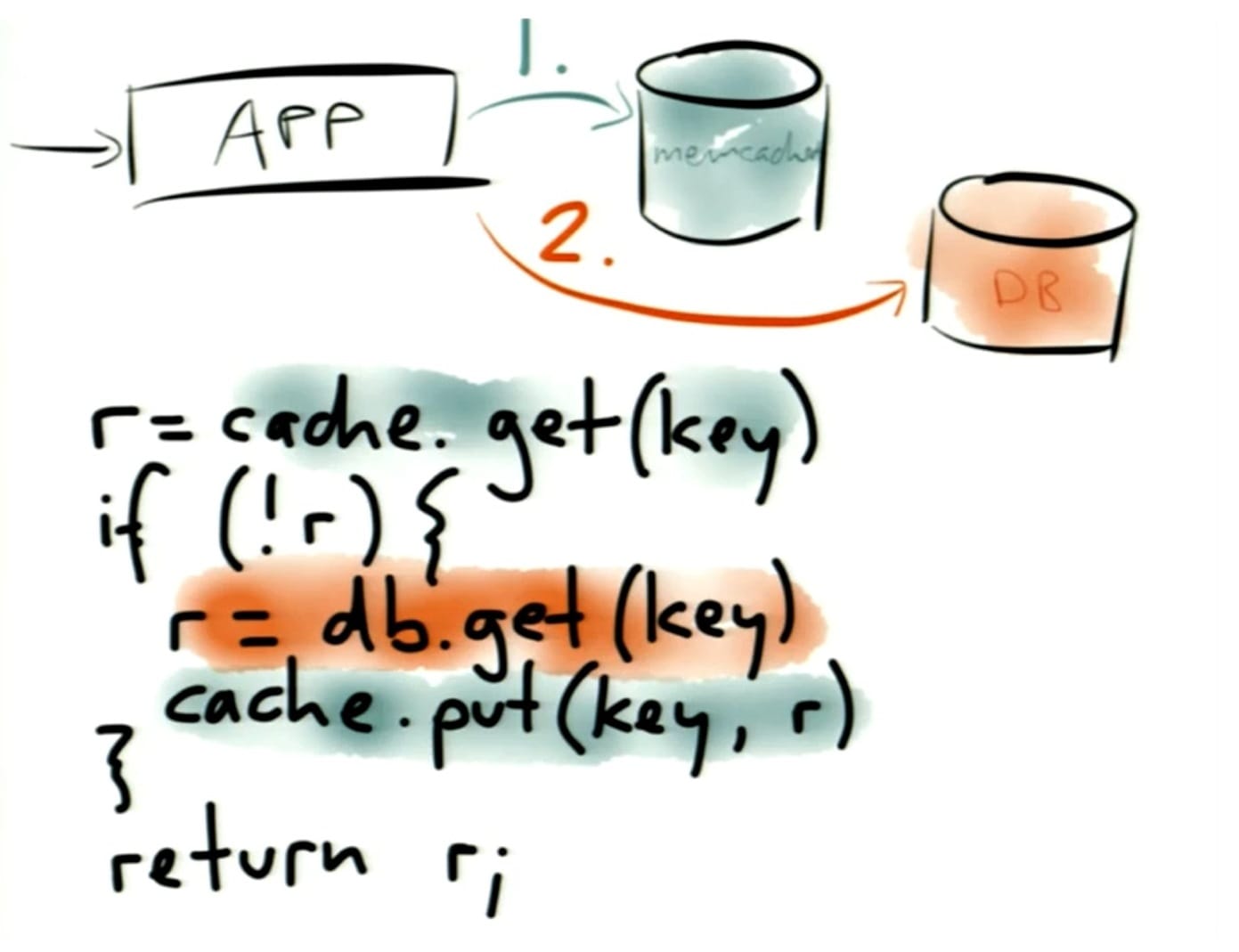
- example #3 – caching – application level caching such as Memcached or Redis that is introduced when the database is getting hit too hard or it's getting too slow
- oftentimes these types of caches get introduced by managing them in application code
- the cache is first searched after an incoming request is received, followed by the database
- this is a pattern that involves a lot of problems
- the first problem is invalidation – how do you know when the cache needs to be updated? perhaps when a write is made to the database, a write is also made to the cache, or you may choose to just expire it, or you may choose to have a TTL and let it fall out of the cache and except stale reads in the meantime
- other problem is that caching is very prone to race conditions – most building these types of applications kind of pretend that race conditions don't exist because it's just too much to think about (a lot of laugher at this comment)
- say there are 2 processes concurrently writing to the same key, and these are both updating the database and updating the cache – they might update the database in one order and the cache in another order – and then the two are inconsistent
- another problem is cold starting/bootstrapping – for example, say you reboot your Memcached servers and they loose their entire contents, and suddenly every request is a cache miss, and so the database starts getting hit heavily
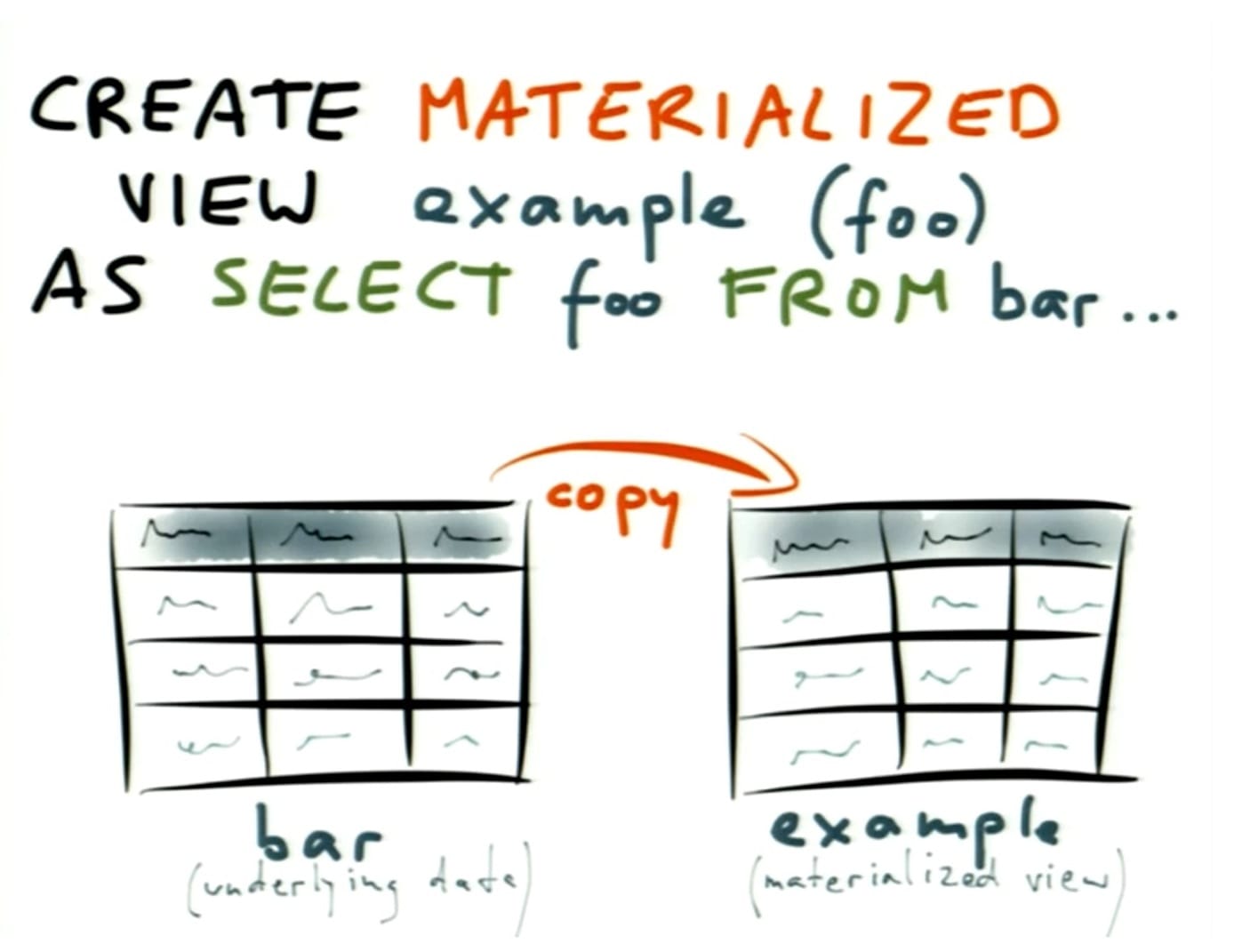
- example #4 – materialized views – a traditional view is defined in terms of a SELECT query, and you can query it like a table, so it acts like a wrapper to a query which is executed at query time – but the implementation for a materialized view is completely different, since it is written to disk and a copy of the data is involved
- if the query is expensive, the query has already been executed ahead of time, but the difference now is that the database needs to maintain this materialized view
- when you think about it, this is somewhat like a cache
- the main difference between this and a cache is that it's maintained by the database, and with an application cache you have a lot more flexibility in terms of what you can do
- all 4 of these examples have the following in common: these are all forms of derived data – taking some underlying dataset and transforming it into something else
- the differences between these are how well each work
- replication is mature, understood well, and works well
- secondary indexes are as well
- caching is a complete mess
- the idea of having materialized views is nice, but rather than taking the load off the database it is actually giving the database more work to do
- the idea behind a materialized view – a cache that magically keeps itself up to date – is compelling, so why don't we rethink this idea? what would the architecture look like?
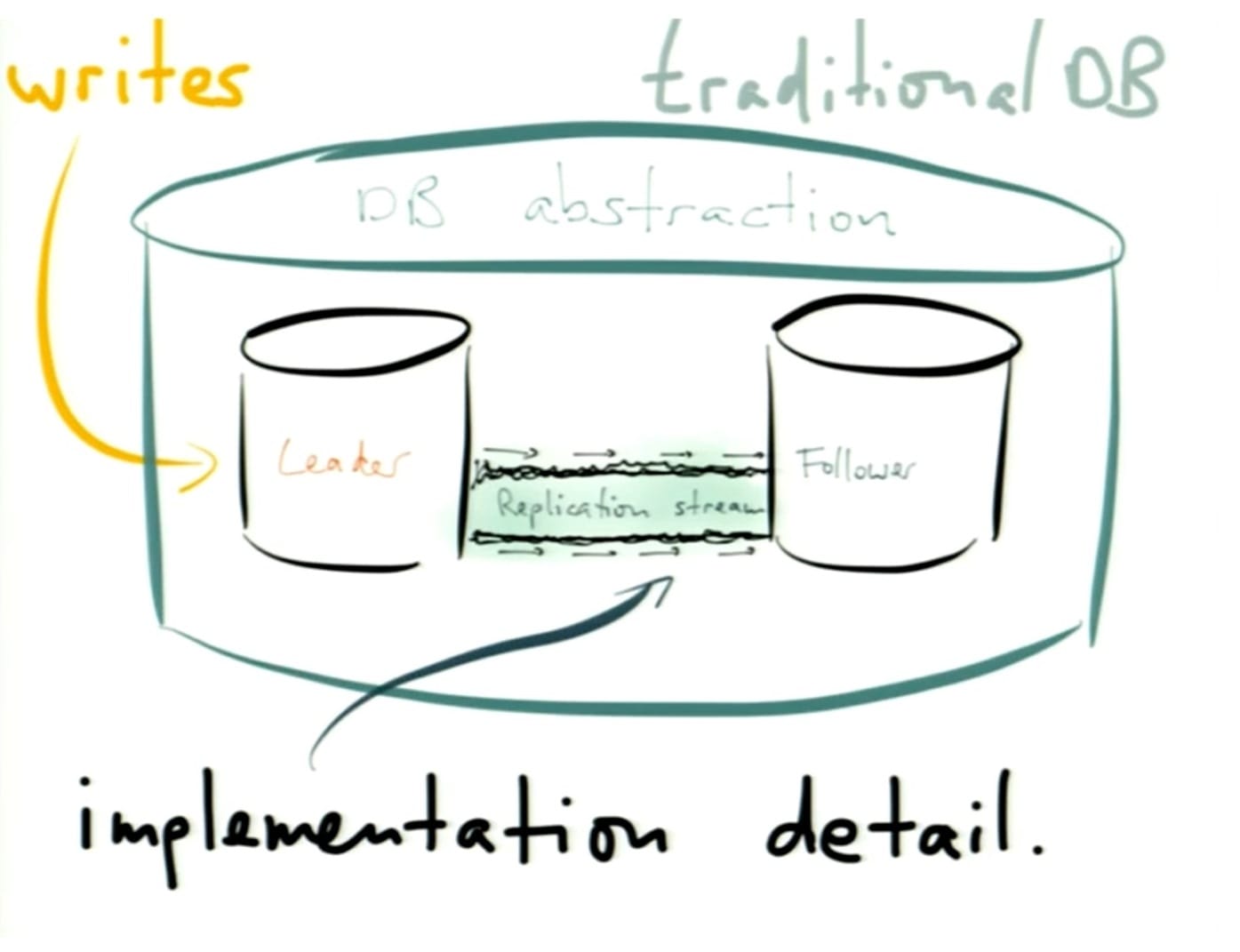
- at this point, Kleppman returned to traditional database architecture with replication
- inbetween the leader and each follower is a stream of updates – and the leader, followers, and stream exist in an abstract package
- the replication stream is really just an implementation detail
- what if we take this internal implementation detail and make it a first class citizen? – this is what Kleppmann means by "turning the database inside out"
- what would this look like? – you could call it a transaction log or event stream
- writes would not need to be made to the leader database, but to the stream, which is a very simple data structure – reading would be simple as well
- Apache Kafka for example does this really well – distributed across multiple machines, fault tolerant, high performance
- once you have this log, you can write to it efficiently, but you can't read from it efficiently – so we need to build indexes, materialized views, caches – we can do this by consuming the stream
- you need a stream processing framework – Apache Samza is one such framework, and it works well with Apache Kafka
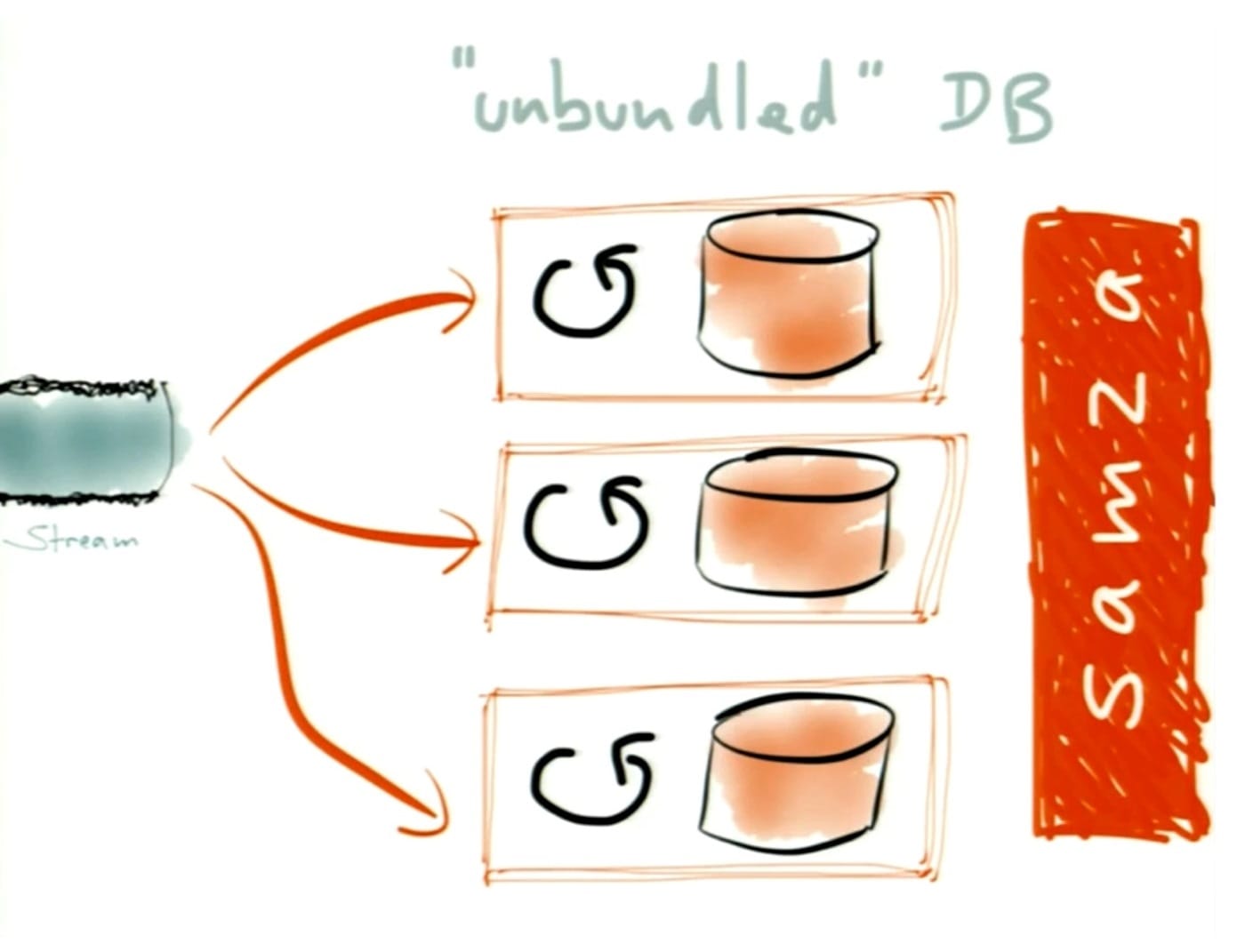
- if you want to build a new materialized view or cache, you can go back in time to the beginning of your log and process everything sequentially from the start, and you can do this in parallel across multiple machines
- conceptually this is very simple
- some have called this the kappa architecture to contrast it with the lambda architecture
- the kappa architecture is similar to the lambda architecture, but doing away with the batch processing part, and saying that if you have a sufficiently powerful stream processing system you can do most of this materialized view building directly in the stream processing system
- if we're going to rework our database architecture and application architecture, since this is a lot of work, what's the point of all of this?
- there are 3 things that this lets us do
- #1 is better quality data
- one problem with shared mutable databases is that they conflate the concerns of the reader and the writer
- so the whole debate about normalization versus denormalization essentially comes down to the decision over whether you want to optimize reading over writing and vice versa
- if you're going to optimize for reading, what is the use case?
- if you separate these out, and writes are just events to a log, then you can build whatever materialized views that you want – your writes can be normalized, and your materialized views can be optimized for reading and you can have different views for different use cases and you can denormalize as much as you want since you can run it anytime
- this provides advantages for analytics, a separation of concerns between reading and writing, writing once and reading from many different views, historical point-in-time queries, and recovery from human error such as bad code being deployed
- #2 is fully precomputed caches
- the materialized view is essentially a fully precomputed cache – there is no such thing as a cold start – there is no such thing as a cache miss – if it's not in the materialized view, it doesn't exist
- there is no cache warming, no hit/miss rate, no race conditions, no complex invalidation logic, better isolation/robustness etc
- #3 is streams everywhere
- if you think about the life cycle of a request using traditional architecture, the raw data will be returned as written to business logic and then written to a cache, the data will be returned to the client, and there will be some user interface code which will render the data, transforming the data again, after which the browser itself renders the data
- the data goes through this series of transformations, and you can think of each of these transformations as a materialized view
- how well does each of these transformations work?
- browser rendering is amazing – it's impressive, and fast
- user interface logic is not quite there yet, but half a dozen talks at this conference revolve around functional reactive programming, and the momentum is going in the right direction
- unfortunately, business logic has traditionally been terrible
- a request is sent to the database, and a response is sent back, representing the current state in time of the database – if the state of the database changes immediately afterward, tough luck, you don't find out about it
- you can poll the database or build some elaborate system to track changes in the database
- some databases have added subscription to changes, but this type of functionality does not really come to mind for most designers
- what if we took all of the materialized views from the log centric architecture and let all of our clients subscribe to them?
- if we could get data flowing really smoothly through all of the layers, we could build some really awesome applications
- right now, Kleppmann thinks that the weakest link in this pipeline is at the database end – the database as well as how applications talk to the database
- we really need to look everywhere in which a request/response is being performed, and rethink all of these to the point that streams exist everywhere
- instead of request/response, use subscribe/notify
- this is a fundamental rethink because the request/response model is so deeply engrained in everything we do
- we should really kill REST APIs because these are not fundamentally publish/subscribe
- there are some frameworks which are trying to work in this direction, such as Meteor and Firebase, but we really need a lot more – we need everyone to be thinking streams everywhere

- in response to a question from the audience as to how we deal with Kafka's at least once delivery, Kleppmann initially responded by saying that updating a materialized view in many cases will be idempotent
- if you just take the latest state of something, and write to a database, it doesn't change if you reprocess it
- if you're doing things like counting, which isn't idempotent, it's a bigger problem
- what is currently in process there is adding transactionality to Kafka itself, the idea that you can transactionally publish messages to Kafka in one go and confirm whether or not they were published correctly based on a transaction ID, even if network connections are lost etc
- in response to a question from the audience as to whether materialized views are updated asynchronously – you can query a traditional database immediately after making a write, and get the results of that write back – Kleppmann initially responded by saying that you are not guaranteed that this will be so in this case
- the most promising approach will be to add transactionality on top of the streaming model
- one reference that Kleppmann forgot to include on his slide is a Microsoft paper on a system called Tango, which involves adding transactionally consistent data structures on top of an asynchronous log
- in response to a question from the audience as to how Samza deals with schema changes over time, Kleppmann initially responded by saying that the best answer he can give right now is to use a serialization format which allows schema evolution like protocol buffers or something like that, and tagging each message with the schema version it is at, and allow updates
- if a publisher publishes messages in an old format, then subscribers still need to be able to understand the old format and vice versa – this is a very solveable problem
- in response to a question from the audience as to where security policy and access permissions fit in, Kleppman indicated that he thinks it should be added at the point where the data is pushed out to subscribers
- if this is running in a stream process, you can run arbitrary code in there – it can do access control checking as you would typically do for example in the back end of a web service
- another question asked whether Samza does schema management
- Kleppmann responded by saying that Samza is agnostic with regard to what type of serialization or data format you want to use – you can plug in JSON for example to serialize your messages
- the creation of a secondary index is not declarative as of yet as it would be in a relational database – you need to write code to do this
- another question asked how Samza is different than Apache Storm, and Kleppman explained that it is another stream processing framework, but that he didn't feel like he could explain the differences well, and so suggested a look at the Samza documentation which explains these differences
- in summary, Kleppmann seemed to be saying that Samza and Storm are better than the other depending on the application
- another question asked about compaction of the log, and Kleppmann explained that Kafka currently supports 2 forms of compaction – one is to throw away data after a certain point in time, which works well for event tracking type data – the second is key based compaction, in which each message is tagged with a key, and the contract is if you write multiple messages with the same key, Kafka can throw away all but the latest of those messages
- someone else asked Kleppmann to provide a comparison with Datomic, and he responded by saying that there are definitely some overlaps
- Datomic also has the idea of immutable facts that you put into the database, as well as a totally ordered stream
- Kleppmann thinks that Datomic still tries to look like a traditional database, which is probably actually good if you want to sell a database system these days (a lot of laugher from audience)
- people still expect to be able to execute random access queries
- Samza is designed to be totally distributed, whereas Datomic has a single node for transaction processing, so all writes have to go through a single node
- another question asked whether Kleppmann has any thoughts around appropriate stores for materialized views, and he explained that Samza comes with a built in abstraction for state
- if all you are doing is taking in messages, and updating some state in those messages, you don't really want to talk over the network to some remote data store for every single message, because the throughput would be horrible
- Samza embeds a key-value store in process on the same machine, and at the moment this is using LevelDB, but the plan is to switch the implementation to RocksDB in the near future
- only the local process has access, but by partitioning you can have each partition of the stream feed into its own partition of the materialized view – anyone who wants to read from that particular partition of the view then needs to go to the appropriate node, so some routing is involved