Media Query Source: Part 28 - TechTarget (US digital magazine); Event streaming technologies a remedy for big data's onslaught
- TechTarget (US digital magazine)
- Data streaming hurdles & best practices
- Concepts challenging for traditional data pros
- Greenfield use cases relatively less complex
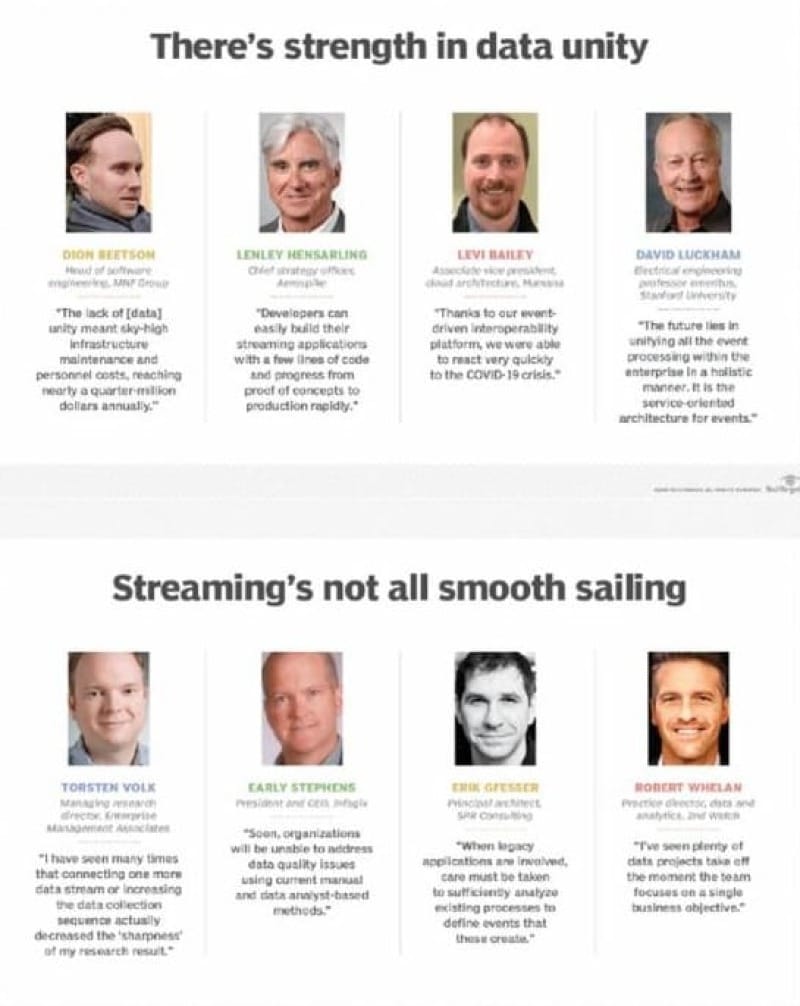
My responses ended up being included in an article at TechTarget (November 25, 2020). Extent of verbatim quote highlighted in orange, paraphrased quote highlighted in gray. Above image from cited article.
This post is for subscribers only
Already have an account? Sign in.